
Met de toenemende wens van organisaties om data gedreven te worden en te blijven, concentreren organisaties zich voornamelijk op het verzamelen en toegankelijk maken van data. Hoe zorg je ervoor dat deze data ook van de juiste kwaliteit is en hoe kan jouw organisatie dat bereiken?
Een hoge datakwaliteit is van groot belang bij het beschikbaar stellen en gebruiken van data samen met de interne organisatie, je klanten & leveranciers en externe regelgevers. De interne organisatie moet steeds vaker en sneller de juiste beslissingen nemen op basis van data. Producten en diensten moeten steeds sneller ontwikkeld worden, waardoor data steeds beter en sneller beschikbaar moet zijn, bij zowel de business als IT. Het aantal externe regelgevingen neemt alsmaar toe en externe regelgevers willen niet enkel de geaggregeerde data, maar steeds meer data op atomair niveau.
Deze trends leggen een prestatiedruk op een organisatie. Ze zijn ook een kans om waarde toe te voegen als de data van hoge kwaliteit is. Een lage datakwaliteit zorgt er voor dat datagedreven initiatieven juist een tegenovergesteld effect kunnen hebben. In dit blog gaan we in op de kosten en baten van een lage en hoge datakwaliteit en hoe datakwaliteitsmanagement in jouw organisatie een gewoonte wordt.
Wat kost een lage datakwaliteit?
Door het steeds breder beschikbaar stellen van data aan doelgroepen, neemt de impact -en daarmee ook de kosten- van een lage datakwaliteit toe. Een lage datakwaliteit zal negatieve impact hebben op het succes van projecten die afhankelijk zijn van deze data. Hoe langer je wacht met het verbeteren van de datakwaliteit, hoe meer tijd, geld en moeite het kost om het op het gewenste niveau te krijgen.
Wat levert een hoge datakwaliteit op?
Het bereiken van een hoge datakwaliteit is geen eenmalige actie. Het vergt continue beheer van de datakwaliteit in relevante databronnen, analyse- en rapportageomgevingen. Het opzetten en daarna continue beheren van de datakwaliteit noemen we datakwaliteitsmanagement.
.png?width=1296&name=Schermopname%20(13).png)
Wat is datakwaliteitsmanagement?
Datakwaliteitsmanagement is, volgens de Datamanagement Body of Knowledge (DM-BOK), de planning, implementatie en het beheer van activiteiten die kwaliteitsmanagementtechnieken toepassen op data om te verzekeren dat data geschikt is voor consumptie en voldoet aan de eisen van datagebruikers. Het is een fundamentele competentie voor elke datagedreven organisatie zoals ook in een vorig blog is beschreven.
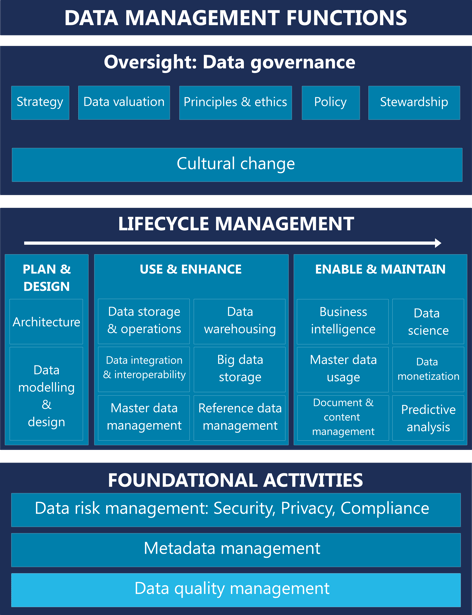
Het opzetten van datakwaliteitsmanagement werkt het beste door een initiële projectmatige aanpak. Voorwaarde voor een succesvol project is dat de data governance rollen binnen de organisatie benoemd zijn. Dit hoeven nog geen uitgebreide taakomschrijvingen te zijn of een compleet data governance programma. Het opzetten van datakwaliteitsmanagement is juist één van de fundamentele activiteiten binnen data governance dat ervoor zorgt dat er invulling aan de data governance rollen wordt gegeven.
In een datakwaliteitsmanagementproject leg je een eerste fundament door het uitvoeren van de volgende activiteiten:
- Definiëren hoge kwaliteit data / datakwaliteitscriteria
- Definiëren van een datakwaliteitsstrategie
- Definiëren scope van initiële assessmenta.
a. Identificeren kritieke data
b. Identificeren bestaande regels en patronen - Uitvoeren initiële datakwaliteit assessment
a. Identificeren en prioriteren van de issues
b. Uitvoeren root cause analyse van issues - Identificeren & prioriteren van verbeteringen
a. Prioriteren verbeteringen gebaseerd op business impact
b. Ontwikkelen van preventieve en correctieve maatregelen
c. Inplannen verbeteringen en maatregelen\ - Ontwikkeling en uitvoering van datakwaliteitsverbeteringen en maatregelen
a. Ontwikkelen operationele procedures datakwaliteit
b. Doorvoeren verbeteringen en maatregelen
c. Meten en monitoren datakwaliteit
d. Rapporteren datakwaliteit
Het uitvoeren van datakwaliteitsmanagementproject kan met elke projectmanagementmethode, van waterval tot scrum en is afhankelijk van wat het best bij jouw organisatie past. Juist vanaf activiteit 3 leent het zich om in kleine iteraties aan de slag te gaan en als organisatie te leren wat hoge datakwaliteit betekent voor jullie en indien nodig om de definities van activiteit 1 en 2 te herzien en te verbeteren.
Na het uitvoeren van deze projectfase volgt de beheerfase; het vasthouden van de bereikte datakwaliteit en zorgen dat een hoge kwaliteit een gewoonte is en blijft bij toekomstige veranderingen. In deze fase worden datakwaliteitsissues gemeld bij een organisatiebreed team, bijvoorbeeld het Data Governance Team, al zijn andere inrichtingen mogelijk gericht op jouw organisatie. Het Data Governance Team beheert deze issues in een backlog en identificeert en notificeert de data-eigenaar(s) van de betrokken data-elementen. Het Data Governance Team rapporteert de datakwaliteitsissues naar de rest van de organisatie.
De data-eigenaren zijn dan verantwoordelijk voor het verhelpen van deze issues. In het geval er conflicten zijn in de prioritering van het verhelpen van deze issues, kan een stuurgroep of Data Governance Committee uitkomst bieden. In onderstaand figuur is te zien wat de life cycle is van datakwaliteitsissues en hoe deze ook zorgdragen dat de operationele procedures datakwaliteit up to date blijven.

Worstel je met datakwaliteit en/of het opzetten van datakwaliteitsmanagement, of wil je meer weten over de onbegrensde mogelijkheden van data? Onze Digital Business unit zorgt er met haar consultants, producten en van onze krachtige BI & Analytics oplossingen voor dat jouw organisatie simpeler, sneller en meer met data kan. Wij zijn continue bezig met de ontwikkeling van nieuwe producten om jouw organisatie te ondersteunen op weg naar een datagedreven organisatie.