In dit tweede deel van mijn blog over ‘wat is data science’ ga ik het hebben over de vernieuwingen uit het laatste decennium en hoe zich dat verhoudt tot de vele buzzwords die hier omheen hangen. Ik begin met het uitdiepen van de term Data Science. Daarna gaan we de buzzwords op zijn plek zetten door de termen kunstmatige intelligentie, big data, machine learning en deep learning naast data science te leggen.
De oorsprong van Data Science ligt in het cijfermatig analyseren van bedrijfsprocessen met als doel deze bedrijfsprocessen te verbeteren. Deze oorsprong wordt ook wel analytics genoemd en hierover heb ik het uitgebreid gehad in het eerste deel van dit blog tweeluik.
Data Science is echter veel meer dan dat. Het vakgebied is sterk beïnvloed door de mogelijkheden van de rekenkracht van moderne computers en de veel grotere hoeveelheden data die we tegenwoordig tot onze beschikking hebben. Daarom wordt rondom Data Science ook vaak gesproken over zaken (of buzzwords) als big data, kunstmatige intelligentie en machine learning.
Data Science
Tegenwoordig hebben we (heel) veel meer data tot onze beschikking dan pak hem beet 10 jaar geleden. En die data bestaat ook vaak uit bijvoorbeeld afbeeldingen, tekst, geluid en filmpjes, de zogeheten ongestructureerde data. Traditionele analytics methoden kunnen zowel met deze hoeveelheid data als dit type data vaak niet uit te voeten. Maar met de enorme hoeveelheid rekenkracht van onze moderne computers (of een cluster in de cloud) kun je wel degelijk wat met deze data doen. En zelfs op één enkele moderne computer met een krachtige grafische kaart, die vaak honderden keren de rekenkracht van je processor heeft, valt al veel te doen.
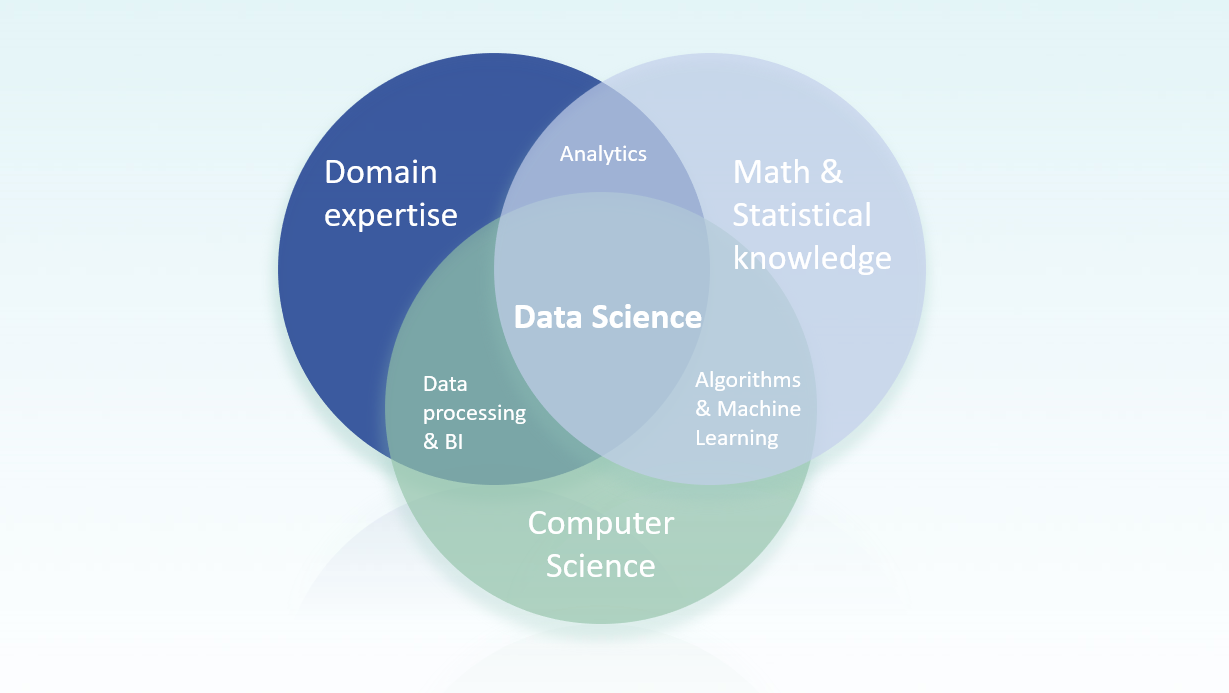
Data Science is dan ook het snijvlak waar het oplossen van bedrijfsvraagstukken, wiskundige- of statistische methoden en algoritmen en krachtige IT en computer science samen komen. Dit in tegenstelling tot de klassieke analytics, waar de computer slechts een hulpmiddel was. Dit wordt mooi geïllustreerd in het figuur hieronder.
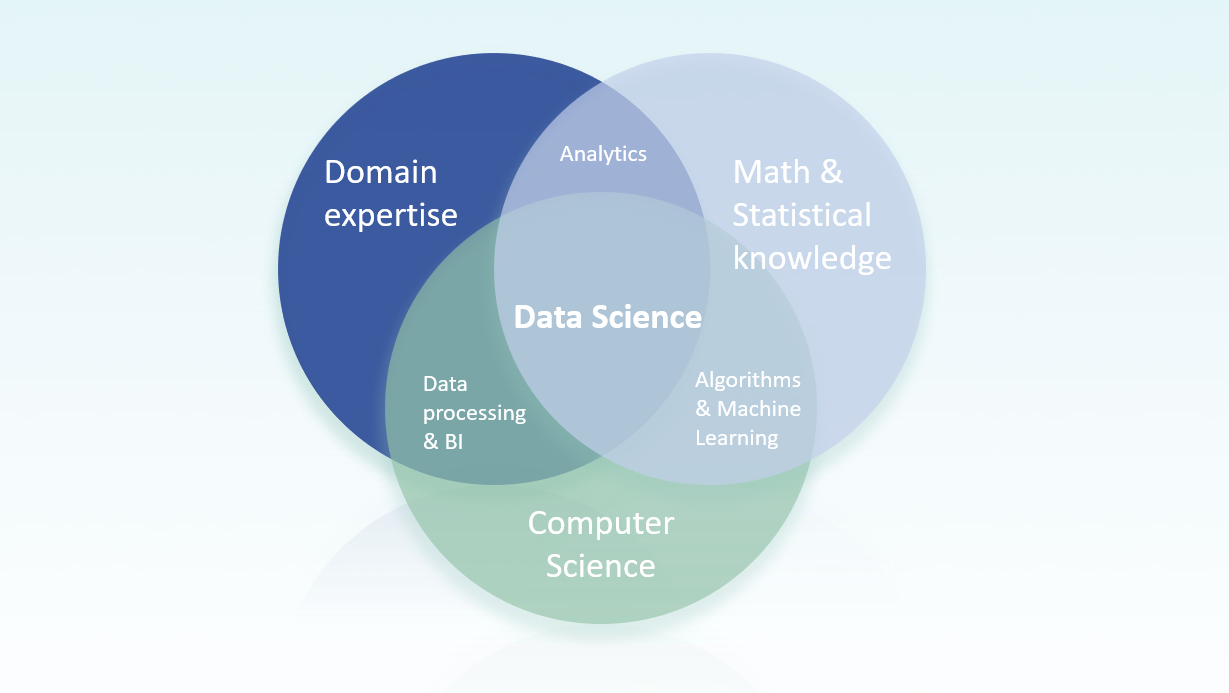
Data Science zit echt in het hart van deze domeinen. Om met hele grote hoeveelheden data, waaronder dus ook afbeeldingen en video’s, te kunnen werken moet je vaak wat van de wiskundige grondigheid opofferen, om vervolgens op basis van grote rekenkracht en slimme IT toch een werkend systeem te kunnen maken. En dan uiteraard een systeem dat waarde heeft in de business context van het vraagstuk.
Om dit voor elkaar te krijgen moet er vaak een hoop gemasseerd worden: ruwe, ongestructureerde data kan niet zomaar een wiskundig model in; methoden en technieken zijn niet altijd één op één toepasbaar op grote datasets. Je moet ook de juist tools hebben die precies die aanpassingen op de standaard techniek ondersteunen, welke nodig zijn voor de Data Scientist om zijn of haar opdracht te voltooien.
Dit is een ambacht op zich, met vele uitdagingen. Ik leg ook niet voor niets vaak de nadruk op dat het Data Science heet. Het kan namelijk een heel onderzoeksproces zijn om tot het juiste model voor de specifieke toepassing te komen. Een onderzoekproces waarin kan blijken dat bepaalde dingen helemaal niet kunnen op basis van je data, of een onderzoeksproces waarin nieuwe business kansen ontstaan juist door te experimenteren met de mogelijkheden met de data. Het is dan ook niet ongebruikelijk dat een dergelijk proces eindigt met een andere eindoplossing dan vooraf gedacht.
Typische voorbeelden van data science vraagstukken zijn:
- Predictive maintenance.
Op basis van data uit sensoren in een productiemachine of -lijn probeer je te voorspellen wanneer onderhoud nodig is. Vaak produceren deze sensoren zo veel data, vooral als je er een hele serie hebt, waardoor klassieke statistische analyse lastig wordt. Daarnaast heb je vaak veel data over tijden waarin het productieproces goed loopt, maar slechts weinig data over wanneer de machine out-of-specs loopt en onderhoud te laat is. Toch is hier met Data Science methoden vaak een oplossing voor. - Automatische visuele inspectie.
Op basis van camerabeelden kun je producten inspecteren en verdachte (wellicht defecte) producten doorverwijzen naar uitgebreide inspectie. Precies deze casus op beelden van spoorstaven heeft mij de Hendrik Lorentz Nederlandse Data Science prijs opgeleverd. Echter zijn hier vele variaties op te bedenken, want camerabeelden kunnen net zo goed uit andere bronnen komen, zoals infrarood, ultrasoon, of andersoortige metingen. - Automatisch e-mails doorsturen naar de juiste afdeling.
Als, bijvoorbeeld op je helpdesk, binnenkomende e-mails eerst door een medewerker gelezen moeten worden voordat deze naar de juiste afdeling wordt doorgestuurd, kan dat een hoop tijd kosten. Niet alleen voor de medewerker, maar ook in doorlooptijd voordat er antwoord komt voor je klant. Automatische tekst-analyse kan helpen deze mails direct door te sturen. En als er dan af en toe eentje op de verkeerde plek terecht komt is dat niet zo erg, want deze kunnen alsnog handmatig doorgestuurd worden. - Analyse van twitterfeeds of reviews op internet.
Misschien wordt er online veel geschreven over je producten. Als je automatische analyse van twitterberichten of online reviews over je producten uitvoert, kun je zien hoeveel er over welke aspecten van je product “gesproken” wordt, om daar vervolgens van te leren of actie op te ondernemen. Alles zelf lezen is namelijk geen doen, maar een overzicht maken zodat je er in je bedrijfsvoering ook echt wat aan hebt is erg waardevol (en overigens een best complexe data science uitdaging, maar die ga ik graag aan).
Machine Learning en Deep Learning
Nu we een beeld hebben van wat data science is, kunnen we beginnen met een aantal buzzwords op zijn plek te zetten. Laten we beginnen met machine learning, oftewel het leren van patronen door machines.
Dit werkt als volgt: Door data op een gestructureerde manier aan een model of algoritme in een computer te voeren, kan de computer hier patronen in vinden (leren) die hij kan gebruiken om voorspellingen te doen (bijvoorbeeld voor predictive maintenance), dingen te classificeren (zoals in de spoorinspectie en e-mail doorstuur voorbeelden), of structuur te ontdekken in deze data (zoals in de twitterfeed voorbeeld). Voor de goede orde, niet alle Data Science is machine learning: als er niets geleerd wordt door het algoritme dan heet dit geen machine learning.
In zijn meest eenvoudige vorm is machine learning gewoon statistiek, want patronen zoeken in data doen statistici al jaren. Maar bij machine learning is men niet altijd geïnteresseerd of alles statistisch precies klopt. Hier gaat het er om, dat als we het geleerde algoritme data geven die het niet eerder gezien heeft, dat het dan nog steeds zinvolle uitkomsten geeft. Voor iedere uitkomst (voorspelling, classificatie, etcetera) precies begrijpen waarom deze tot stand komt wordt hier soms als minder belangrijk gezien.
Een goede Data Scientists moet deze machine learning methoden wel goed begrijpen. Niet om iedere uitkomst precies te verklaren, maar wel om een keuze te kunnen maken tussen verschillende methodieken en alles wat daar bij aan te passen is. Daarnaast geldt altijd dat de uitkomsten nooit beter worden dan de data die er in gaat: een geleerd model is nooit slimmer dan de data die de leraar (de Data Scientist) het geeft om van te leren.
Naast machine learning spreekt men tegenwoordig vaak over deep learning. Dit is machine learning op basis van één specifieke techniek, namelijk die van de neurale netwerken. Typisch gebruik je deze techniek als je modellen maakt die met plaatjes of geluid moeten werken, daar werken ze erg goed namelijk.
Nadeel van deze neurale netwerken is wel dat het vrijwel volledige black-box modellen zijn. Daardoor is het moeilijk om inzichtelijk te maken waarom een deep learning model een bepaalde uitkomst geeft. Ook kunnen neurale netwerken nuttig zijn als je een model wilt maken waarbij juist net nog dat laatste beetje extra accuraatheid (of varianten daarop) belangrijk is, in tegenstelling tot het begrijpen waarom.
Mijn collega Data Scientist Agis heeft een tijdje terug een leuke blog geschreven over onder andere Machine Learning dus wil je meer weten, lees dit.
Kunstmatige Intelligentie
De genoemde Data Science voorbeelden roepen bij velen ideeën op over kunstmatige intelligentie. En machine learning voelt al helemaal als kunstmatige intelligentie. Dus hoe verhoudt zich Data Science nu tot wat we kunstmatige intelligentie noemen?
Laat ik beginnen met vertellen dat kunstmatige intelligentie of AI (van het Engelse Artificial Intelligence) een term is die heel weinig concreets betekent. Dit komt deels omdat het kunstmatige intelligentie onderzoek al heel erg oud is. Wat men vroeger al heel intelligent vond, daar vinden we nu niets slims meer aan. Als een ‘slim’ algoritme een set voorgeprogrammeerde beslisregels volgde, werd dit vroeger als kunstmatige intelligentie gezien. Maar ook tegenwoordig wordt de term kunstmatige intelligentie te pas en te onpas gebruikt: soms betekent het machine learning, velen gebruiken het als synomiem voor deep learning en anderen weer voor alles wat data science is.
Toch heeft moderne kunstmatige intelligentie iets, wat niet direct onder andere terminologieën te vangen is. Moderne kunstmatige intelligentie is namelijk ook het bouwen van software bestaande uit vele verschillende componenten die samen iets heel intelligents lijken te doen. Vaak bevatten deze meerdere componenten die gewone data science modellen zijn. Dit in tegenstelling tot de meeste Data Science modellen die zich vaak op één taak richten.
Een mooi voorbeeld hiervan zijn zelfrijdende auto’s: de gebruikte beeldherkenningssystemen (zodat je nergens tegenaan rijdt) staan volledig los van de navigatiesystemen (wat is de beste route) en de resultaten van deze systemen worden in een beslissingseenheid samengevoegd tot wat de auto daadwerkelijk doet. De auto als geheel lijkt heel intelligent, maar bestaat uit losse, wellicht minder spectaculaire, Data Science componenten.
Voor een data scientist is het relevant dat partijen als Microsoft en Google verschillende modellen kant en klaar aanleveren, die een Data Scientist vervolgens kan combineren met zijn eigen modellen. Zo zijn er standaard modellen om tekst in plaatjes te lezen, geluid om te zetten in tekst of vice versa, gezichten te herkennen (en of iemand een man of vrouw is en hoe oud ongeveer), of anderszins objecten in afbeeldingen te herkennen en te beschrijven.
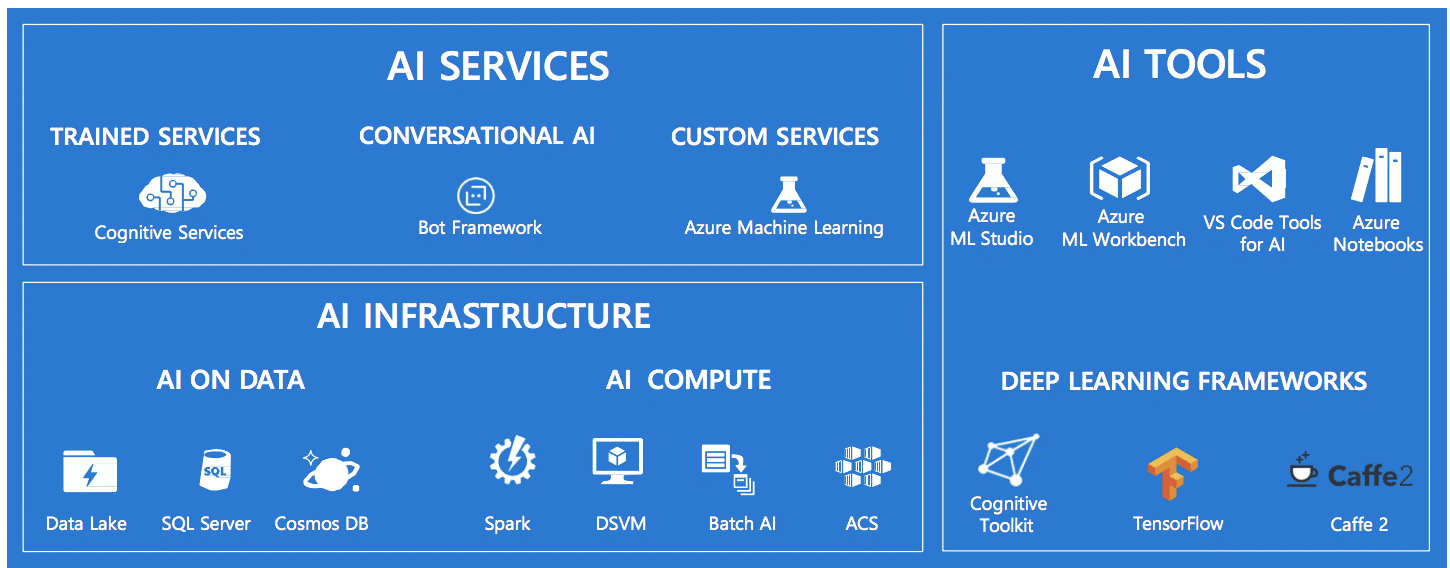
Of deze standaard modellen goed genoeg zijn om een eigen stukje moderne kunstmatige intelligentie te ontwikkelen hangt sterk af van de toepassing. Neem onderstaand plaatje. Voor jou en mij is het vrij duidelijk dat dit een overzicht is van de kunstmatige intelligentie tools die Microsoft aanbiedt. Als je deze afbeelding in Word (Lees: een Microsoft tool) plaatst en 'automatische alternatieve tekst' aanklikt, geeft Word - met behulp van Microsoft Cognitive Services - een omschrijving. Afbeeldingsherkenning én -beschrijving dus. Het resultaat is in dit geval wat tegenvallend, volgens Word is dit: ‘Schermafdruk van een mobiele telefoon’...
Big Data
Om te eindigen met misschien wel het meest gebruikte buzzword van de afgelopen jaren: big data. Als er één uitdrukking rondom Data Science is die voor verwarring zorgt dan is het big data. Ik ben er namelijk eens op gaan letten en volgens mij kan ‘big data’ drie verschillende dingen betekenen.
- Gewoon Data Science.
Mensen die niet bekend zijn met het vakgebied noemen ieder stukje Data Science gewoon Big Data. Google eens ‘plannen met big data’ en je vindt allerlei voorbeelden van Data Science waarbij op geen enkele manier echt veel data gebruikt wordt, of iets anders aan de hand is wat de term ‘big data’ rechtvaardigt. - Data Science (of BI) waarbij de hoeveelheid data die gebruikt wordt te groot is voor één computer.
Typisch lees je dan over de 3 (of 4, of 5) V’s: namelijk het volume van de data (meer dan één computer), de velocity of snelheid waarmee deze geproduceerd wordt (meestal door IoT-sensoren) en de variëteit (afbeeldingen, tekst, video etcetera). Als je zoveel data hebt dat het niet meer in één computer past heb je hier speciale software voor nodig die op clusters van computers draait: dit is echt big data! - Data Science waarin publiek beschikbare databronnen gebruikt worden.
Twitterfeeds, product reviews op internet, data van bijvoorbeeld het CBS of openbare geo-informatiebronnen, of zelfs het hele internet zelf. De term big in big data verwijst hier naar hoe groot het internet is en hoeveel informatie daar beschikbaar is.
Voor een Data Scientists is het bij ‘big data’ vooral van belang door te hebben welke betekenis bedoeld wordt. Daarnaast zijn er voor de echt hele grote dataset speciale big data tools, zonder welke je anders echt niet kunt werken. Echter vergen dergelijke tools ook een specifieke andere benadering van je probleemstelling: want sommige simpele berekeningen die net wat lastiger zijn dan het uitrekenen van een gemiddelde, kunnen op echt heel grote datasets al knap lastig zijn. Misschien wijd ik hier in de toekomst nog een blog aan, maar het voert wat ver om hier nu dieper op in te gaan.
Tot slot
Mijn doel met dit en voorgaande blog is een idee geven van wat Data Science is; wat voor business problemen je hiermee kunt oplossen; en hoe data science zich verhoudt tot de verschillende buzzwords als kunstmatige intelligentie, big data en machine learning. Zeg maar een behapbaar overzicht dat praten over Data Science makkelijker maakt. Vooral voor als het niet je vak is.
Ik hoop daar een beetje in geslaagd te zijn. Ik ben benieuwd naar je mening, dus mis je iets, wil je meer informatie over een specifiek onderwerp of een keer brainstormen over wat Data Science voor jou kan betekenen; laat het me weten!
