
Voorspellend onderhoud is een hot topic. Maar wat houdt voorspellend onderhoud nu precies in? Wat maakt het zo interessant? En misschien nog wel de belangrijkste vraag: hoe pak ik het aan? Als data scientist beginnen m’n handen meteen te jeuken als we het over dit onderwerp hebben, dus ik neem je in dit stuk mee hoe we met behulp van data voorspellend onderhoud realiteit kunnen maken.
Predictive maintenance
Zul je net zien, heb je een deadline voor een belangrijke klant en gaat je machine onverwachts kapot waardoor de order niet op tijd af is. Dit is iets wat je ten alle tijden wilt voorkomen, en dat kan door gebruik te maken van predictive maintenance (de hippe Engelse term die iedereen gebruikt voor voorspellend onderhoud).

Soorten onderhoud
“In the long run, all machines breakdown”, waren de woorden van de bekende econoom Keynes (bekend van het Keynesiaans Model). Alle machines slijten beetje bij beetje en dus is onderhoud iets waar vele bedrijven zich dagelijks mee bezig moeten houden. De truc is om hier zo goed en effectief mogelijk mee om te gaan: enerzijds het minimaliseren van de kosten bij stilstand van de machine (door onderhoud of breakdown) en anderzijds het maximaliseren van de tijdspanne tussen twee onderhoudsbeurten.
In het algemeen zijn drie vormen van onderhoud te onderscheiden: correctief onderhoud, preventief/cyclisch onderhoud en voorspellend/conditie-gebaseerd onderhoud.
Correctief onderhoud is het uitvoeren van onderhoud op het moment dat de machine uitvalt. Preventief onderhoud wordt gepland en dus periodiek uitgevoerd (het wordt ook wel cyclisch onderhoud genoemd). De eerste vorm van onderhoud kenmerkt zich door hoge kosten vanwege ongeplande stilstand. De tweede vorm van onderhoud heeft dan weliswaar minder ongeplande stilstand, maar desalniettemin nog steeds geen minimale downtime-kosten. En wat te denken van onderdelen die preventief worden vervangen, maar die eigenlijk nog best een tijd mee hadden gekund?
Dát is de belofte die voorspellend onderhoud doet; een optimale inzet van onderhoud waardoor downtimekosten wordt geminimaliseerd en resources zo efficiënt mogelijk worden ingezet.
Voorspellend onderhoud; doe het met data
Leuk en aardig, dat voorspellend onderhoud, maar hoe werkt het nou? Dat leg ik uit aan de hand van dit voorbeeld:
We gaan er voor het gemak even vanuit dat er historische data van de machine beschikbaar is. De data kan bestaan uit metingen van sensoren die op de machine geplaatst zijn (bijvoorbeeld temperatuur, druk, aantal rotaties, etc.). Kort gezegd; we kunnen zien hoe de machine presteert op het moment dat ‘ie het doet. We kunnen ook zien welke invloed onderhoud heeft op de prestatie van de machine, bijvoorbeeld dat een bepaald onderdeel ná onderhoud minder snel warm wordt of minder trilt. Als we maar genoeg data hebben, kunnen we patronen ontdekken en kunnen we bepalen hoe belangrijk die temperatuur of trilling is voor de levensduur van de machine. Voor het herkennen van deze patronen kun je verschillende methodes gebruiken, zoals een simpele visualisatie een statistische analyse of Machine/Deep Learning. Deze inzichten zorgen ervoor dat je kunt voorspellen wanneer onderhoud nodig is.
Data
De data van de machines zijn een belangrijke factor binnen het voorspellend onderhoud. Industrie 4.0 heeft z’n intrede gemaakt en machines zijn tegenwoordig steeds vaker ‘smart’ of ‘connected’ en genereren bakken met data.
Oké, de hoeveelheid beschikbare data is dan wel enorm toegenomen, maar het is niet vanzelfsprekend dat deze data altijd makkelijk te gebruiken is voor het toepassen van voorspellend onderhoud. Wanneer je bijvoorbeeld geen historische data hebt, of je huidige onderhoud werkt zo ‘goed’ dat een machine nog nooit ongepland heeft stilgestaan, dan wordt het een stuk complexer. Maar níet onmogelijk! Om in dit geval toch de vruchten te plukken van predictive maintenance, zouden meer domeinkennis of ‘Anomaly Detection’ een uitkomst kunnen zijn, maar het voert te ver om daar in deze blog op in te gaan.
Aan de slag!
Goed, terug naar de machine met historische data. Hoe ga je te werk? Ik geef je vijf handvatten.
1 - Data visualisatie
Het is heel belangrijk om te weten wat er allemaal in die bak met beschikbare data zit. Een goede manier om hierachter te komen is het visualiseren van de data, waarin je de metingen van een sensor afzet tegen de tijd. Misschien zijn er bepaalde trends te ontdekken of is er een verband te zien tussen de trends van metingen van verschillende sensoren. Het helpt om metingen met dezelfde eenheid, waar mogelijk, bij elkaar in dezelfde grafiek te zetten. Het interactief maken van de visualisaties, door bijvoorbeeld het gebruik van Microsoft Power BI, helpt ook om meer overzicht te creëren.
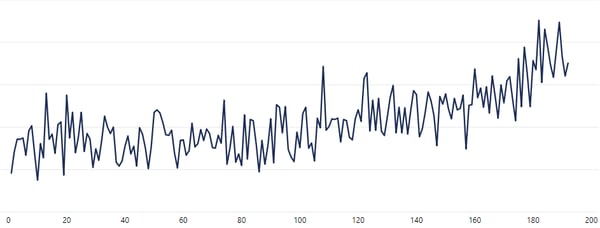
Reeks van sensormetingen weggezet tegen de tijd
Als je per meting de resterende levensduur van een machine weet, is er nog een andere visualisatie die nuttig kan zijn. In dit geval kun je per sensor een histogram maken waarin je kunt laten zien wat de verdeling van de sensormetingen is voor een bepaalde resterende levensduur.
Neem bijvoorbeeld de afbeelding hieronder, waarin de lengte van iedere staaf aangeeft hoe vaak een bepaalde waarde (weergegeven op de horizontale as) in de sensormetingen voorkomt. In de rechter histogram is het gemakkelijk te onderscheiden of de waarde behoort tot een resterende levensduur van 1 (blauw) of 25 (grijs) tijdseenheden; je ziet dat metingen met waarde 0,8 bijna zeker behoort tot een resterende levensduur van 1. In de linker histogram zie je juist dat er veel meer waardes behoren tot beide resterende levensduren (bijv. de waarde 0,5). Dit geeft aan dat de waardes van de sensor uit de rechter histogram veel interessanter zullen zijn voor voorspellend onderhoud.
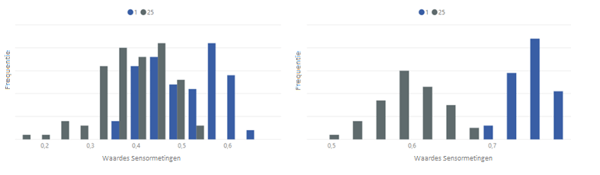
Histogrammen met op de horizontale as de verschillende sensormetingen en op de verticale as de frequentie van iedere meting.
2 - Data-normalisatie
Op een machine kunnen wel tientallen sensoren zitten, die allemaal iets anders monitoren. Deze verschillende sensoren hebben dus ook te maken met verschillende eenheden, zoals bijvoorbeeld temperatuur of druk. Dit zorgt ervoor dat de bandbreedte van de metingen per sensor verschilt; zo kan een bepaalde warmtesensor temperaturen meten tussen de 50 en de 60 (Graden), terwijl een druksensor waardes meet tussen de 100 en 150 (Bar). Om goed te kunnen vergelijken is data-normalisatie belangrijk; je schaalt alle metingen naar eenzelfde bandbreedte (vaak tussen 0 en 1). Simpel voorbeeldje: als 0 en 80 Graden Celsius de 'min' en de ‘max’ zijn en 0 en 200 Bar ook, schaal je 60 graden op 0,75 en 100 Bar op 0,5. Het normaliseren helpt ook verderop in het proces als je Machine Learning wilt toepassen. Het geeft een beter beeld van de invloed van een factor op de voorspelde resterende levensduur.
3 - Dimensie reductie van data
Soms zie je door de bomen het bos niet meer. Een veelvoud aan sensoren, een veelvoud aan metingen en dus een veelvoud aan dimensies. Misschien gebruik je wel te veel sensoren! Als de temperatuur binnen in een machine stijgt kan het aannemelijk zijn dat alle warmtesensoren ook een stijgend patroon aangeven (dus dan waren de data van één warmtesensor misschien wel voldoende geweest). Om hierachter te komen gebruiken we de Principale Componenten Analyse. Dit is een statistische methode waarmee we patronen kunnen herkennen en die de overlap, die je net las in het temperatuur-voorbeeld, elimineert. Om door de bomen het bos weer te zien, kappen we in dit geval dus het hele bos en planten we nieuwe – en minder – bomen. Uiteindelijk resulteert deze methode in minder data/variabelen, maar in evenveel informatie.
4 - Data smoothing
De metingen van een sensor gaan vaak niet gestaag of geleidelijk. Het kan zo zijn dat metingen gedurende de tijd omhoog en omlaag schieten. Ondanks deze “ruis” kan er een patroon of trend te herkennen zijn. Het idee hier is om te kijken of er een lijn door de reeks van de metingen gefit kan worden (zie grafiek hieronder). Deze lijn kan een indicatie geven van de algemene stijging/daling van de metingen, wat bruikbare informatie is. Neem als voorbeeld een pan met water die je op het vuur zet (als metafoor voor onze slijtende machine), waarbij het kookpunt het moment van breakdown is. Als je weet hoeveel graden het water in de pan is, weet je hoever hij van z’n kookpunt af zit. Maar je weet níet hoelang het duurt voor hij z’n kookpunt bereikt. Daarvoor moet je weten hoe hoog het vuur staat en dus hoe snel de temperatuur stijgt.
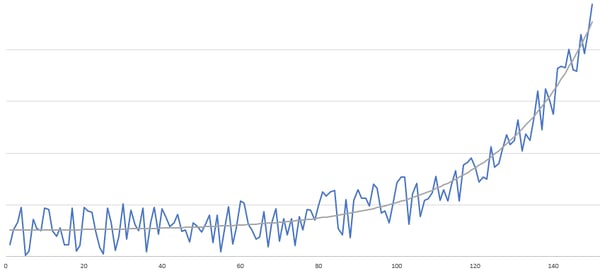
Een gefitte lijn (grijs) door de werkelijke reeks van metingen (blauw)
5 - Start Simpel
Dit laatste handvat is bedoeld om je data nog beter te begrijpen. Ondanks dat er in de wereld van Machine/Deep Learning vele technieken zijn die je kunnen ondersteunen bij dit probleem, is het beter om simpel te starten. Met simpel bedoel ik in dit geval een simpele techniek die voorspelt wanneer er onderhoud nodig is. Waarom? Met dit soort technieken is het vaak gemakkelijker om inzicht te krijgen in de invloed van de inputvariabelen (meting van de sensoren) op de outputvariabele (resterende levensduur).
In tegenstelling tot het bovenstaande zou je bijvoorbeeld ook een neuraal netwerk kunnen pakken om te voorspellen wanneer onderhoud nodig is. Deze Deep Learning techniek probeert zelf informatie uit de input te halen en deze te gebruiken bij de beslissing voor voorspellend onderhoud. In dit geval heb je geen idee welke input belangrijk is voor het maken van de beslissing en weet je dus ook niet of het de juiste beslissing is (er bestaat namelijk een risico dat deze techniek de verkeerde informatie uit de input haalt). Daarom is, zeker als je pas net start met dit onderwerp, een simpele techniek verstandiger om te gebruiken voor het begrijpen van je data.
Laat me weten hoe jij er over denkt!
Starten met voorspellend onderhoud is makkelijker gezegd dan gedaan. Maar als je het goed doet, simpel start en het gestructureerd aanpakt ben ik ervan overtuigd dat het gebruik van data ook jou gaat helpen om productie-uitval te voorkomen. Ik ben benieuwd naar waar jij kansen ziet, laat het vooral weten in de comments. De data scientist in mij wilt niets liever dan de hele dag bezig zijn met dit soort vraagstukken dus als je behoefte hebt om eens te bomen over dit onderwerp hoor ik het natuurlijk ook graag!
