
Veel organisaties kennen een "tweestromenland" in het datagebruik. Om operationele beslissingen en processen te ondersteunen moeten gestructureerde gegevens uit de bedrijfsapplicaties beschikbaar zijn. Maar voor exploratieve analyses en het ontwikkelen van AI-toepassingen is het belangrijk dat ook ongestructureerde data voorhanden zijn. Hoe zijn die verschillende informatiebehoeften te verenigen in één architectuur?
De waarde van een data warehouse
De applicaties waarmee een organisatie werkt hebben allemaal hun eigen database. Met name als verschillende bronnen worden gebruikt voor één centrale toepassing is het aan te raden om deze te consolideren in één database.
Door de gegevens gestructureerd op te slaan, kunnen ze eenvoudig beschikbaar worden gesteld voor een specifieke taak, bijvoorbeeld een financiële rapportage. Bovendien zijn de data in een data warehouse beter te valideren. Dat legt een solide basis voor het implementeren van een data governance policy en het vereenvoudigt de autorisatie van systeemgebruikers.
Daarnaast voorkomt een centrale en gecontroleerde data-omgeving dat er ‘verschillende versies van de waarheid’ ontstaan waardoor beslissingen niet goed onderbouwd worden.

De meerwaarde van een data lake
Een data lake is de verzamelplaats voor alle soorten gegevens. Je kunt er niet alleen data in opslaan die bedrijfsapplicaties genereren, maar bijvoorbeeld ook tekstbestanden, mailberichten, log files en social media berichten.
Omdat de gegevens niet gestructureerd zijn opgeslagen, biedt het gebruikers alle vrijheid om ze te analyseren. Daardoor kunnen verborgen verbanden aan het licht gebracht worden die zijn te gebruiken om voorspellende modellen te ontwikkelen. Denk hierbij aan data scientists die bezig zijn met predictive modelling en het ontwikkelen van AI-toepassingen. Of neem marketeers die sweet spots in kaart willen brengen waarbij ze grote hoeveelheden klant- en verkoopgegevens willen combineren met big data.
Om de variabelen en de relaties daartussen te vinden is het zaak dat er geen beperkingen zijn bij het destilleren en analyseren van data. Daarin ligt de meerwaarde van een data lake.
Een architectuur die alle databehoeften afdekt
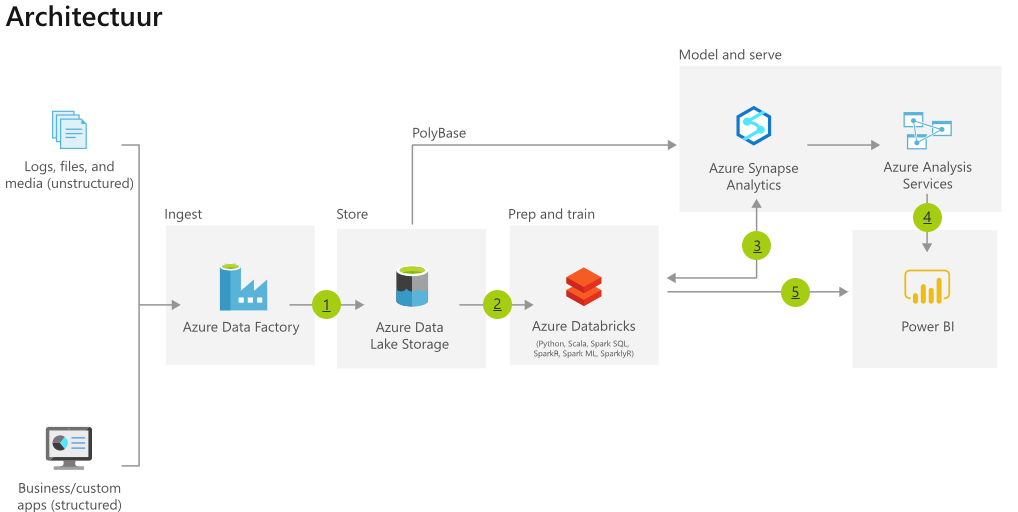
Onder meer Microsoft Azure biedt een architectuur die de data-behoeften voor AI én BI vervult. Zowel gestructureerde data van bedrijfsapplicaties als ongestructureerde logs, files en media stromen dan het data lake in.
Voor het samenbrengen van al die data is bijvoorbeeld Azure Data Factory te gebruiken. Het data lake kan vervolgens voor twee doeleinden ingezet worden.
Enerzijds kan het als voedingsbron dienen voor een data warehouse, dat met Azure Synapse Analytics is te doorzoeken. Vervolgens kan hierover vanuit Power BI gerapporteerd kan worden. Daarnaast kan het data lake benut worden voor data science toepassingen. Het levert dan input voor Azure Databricks. Daarbij komt nog een integratie met Azure Machine Learning in Azure Synapse Analytics. Zo ontstaat één centrale plaats voor je data warehouse en je getrainde modellen.
De moraal van dit verhaal
Het is niet meer nodig om afzonderlijke configuraties op te zetten voor AI en BI. Onder andere Microsoft Azure biedt een architectuur die beide data-doelen ondersteunt met een data lake als voedingsbron. Meer weten over deze oplossing? Laat het me weten in de comments!
