De Algemene Verordening Gegevensbescherming (AVG), de Europese privacywet die zo’n beetje elk bedrijf raakt, wordt vanaf mei volgend jaar gehandhaafd.
In vier stappen kunnen bedrijven een flinke stap zetten om op tijd compliant worden.
Grote stap, snel thuis

In een vorige blog hebben we het kader geschetst. Nu lichten we de eerste - en gelijk ook de grootste - stap toe, die van Inventarisatie. In deze stap wordt het vliegwiel naar duurzame compliance op gang gebracht. Als dat eenmaal draait, komt het bereiken van compliance in de versnelling.
![]()
Om het geheugen op te frissen: de AVG is in het leven geroepen om de consument te beschermen tegen het ongebreidelde verzamelen en commercieel gebruiken van hun data door internetgiganten, marketingbedrijven en media. De AVG regelt de bescherming van persoonsgegevens. Dat zijn data die direct of in combinatie leiden tot identificatie van betrokken individuen. Het gaat om heel gewone data: naam, woonplaats, telefoonnummer… dat soort gegevens. Maar ook CV’s, foto’s, bankgegevens van klanten en medewerkers, kopies van identiteitsbewijzen, social media posts van medewerkers, e-mail. Kortom zo’n beetje alles wat rondgaat in een bedrijf. Consumenten hebben voortaan recht op inzicht in, en inspraak over wat er met hun persoonlijke data gebeurt. Het mag duidelijk zijn dat er nog heel wat werk zal moeten worden verzet om in mei 2018 compliant te zijn. Maar als organisaties de onderstaande vier stappen volgen, is duurzame compliance gewaarborgd.
![]()
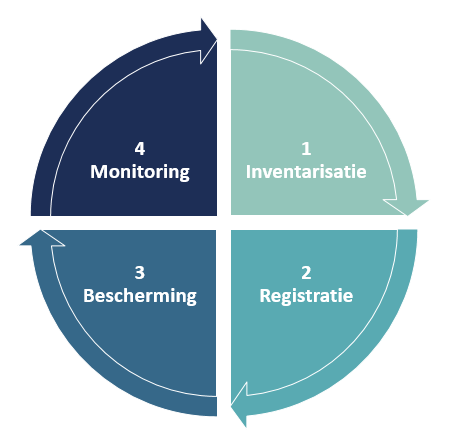
AVG-compliance in vier stappen

Stap 1: Inventarisatie
De andere stappen worden de komende weken uitgewerkt in opeenvolgende blogs.
Welke persoonsgegevens bevinden zich binnen de organisatie? Hoe ziet het volledige datalandschap van het bedrijf eruit? Welke risico’s rond privacy van betrokkenen vormen deze persoonsgegevens? Het uitvoeren van de Inventarisatie is gelijk de meest arbeidsintensieve stap. Als deze met succes is afgerond, zijn de vervolgstappen sneller te zetten. Vergelijk het met een kerstboom. Iedereen die wel eens een kerstboom in huis heeft gehaald en opgetuigd, weet dat het uitzoeken, vervoeren en mooi rechtop neerzetten van de boom het meeste werk is. Het daarna ophangen van de ballen, de kaarsjes en het engelenhaar is zo gedaan.
De Inventarisatie wordt uitgevoerd door middel van een drietal subactiviteiten:
- Het zoeken naar en identificeren van persoonlijke gegevens in de bedrijfssystemen;
- Kijken naar de inhoud van de gegevens en deze classificeren;
- Bewerkingsregister maken en bijhouden.
![]()
Discovery
Bedrijven werken met zowel gestructureerde als ongestructureerde data. Gestructureerde data zijn meestal te vinden in de databases van bedrijfsapplicaties zoals ERP en CRM. Bij ongestructureerde data kun je denken aan foto’s, tekstbestanden, scans van bijvoorbeeld paspoorten, e-mails etc. Beide typen data vragen een specifieke maar integrale compliance- en beveiligingsaanpak. In een separate blog komen we terug op ongestructureerde data.
Eerst dient gekeken te worden in hoeverre de organisatie in staat is een compleet beeld te krijgen van de persoonsgegevens in beheer, in servers, cloud, gehost bij derden. Het bedrijf is zelf de expert van zijn eigen omgeving, dus dat moet het weten. In de praktijk blijkt dat die expertise niet in alle gevallen op orde is. Als we dit constateren, ontstaat bij het bedrijf acuut awareness van de urgentie om dit tekort aan te pakken. Afhankelijk van de maturity van een organisatie kan de Discovery-stap in twee tot zes maanden zijn afgerond.
Het eindproduct van deze activiteit is de datalocatiecatalogus, waarin de plaats en de aard van data is vastgelegd; het is een tussenproduct op weg naar het bewerkingsregister. De datalocatiecatalogus zal voor het grootste deel handmatig moeten worden aangemaakt. Automatisering - bijv. via door BI-architecten gecreëerde workflows - is een nice to have en kan altijd later worden opgepakt.
Classificatie
Na Discovery worden de gevonden data op gevoeligheid geclassificeerd op basis van de labels ‘Openbaar’, ‘Vertrouwelijk’ (bijv. naam van de klant of medewerker), ‘Geheim’ (bijv. woonadressen) of ‘Strikt Geheim’ (bijv. creditcardnummers). In de praktijk blijken deze vier labels te volstaan. De classificatie brengt ook in kaart waar NAW- en betalingsgegevens staan. Classificatie maakt verder inzichtelijk hoe het beveiligingsbeleid kan worden gedifferentieerd. Vertrouwelijke gegevens vragen immers andere beveiliging dan strikt geheime informatie.
Bewerkingsegister
Al deze informatie, ook die uit de datalocatiecatalogus, komt in het verplichte bewerkingsregister. Dit is het totaaloverzicht van de gevonden instanties, data en classificaties. Maar ook van wat er met de data gebeurt: lezen, schrijven, bijwerken en verwijderen. En hoe de beveiliging is opgezet. Dit alles moet goed gedocumenteerd worden, net als de afspraken over databeheer die zijn gemaakt met partijen binnen en buiten de organisatie.
De AVG vereist dat je organisatie in staat is te rapporteren aan de toezichthouder over de oorsprong van data: hoe kom je aan de data? Zijn ze verstrekt door de belanghebbende zelf of zijn ze via een andere weg verkregen? Hoe dan? Op welke wijze heeft de belanghebbende toestemming gegeven voor het verzamelen van de data? Die informatie is onder meer belangrijk om in geval van datalekkage het punt te kunnen herleiden waar het mis ging (root cause analysis).
Het is zaak om processen in te richten voor het actueel houden van het bewerkingsregister.
![]()
Hulpmiddelen en professionele ondersteuning
Voor het maken en bijhouden van de datalocatiecatalogus werken wij bij voorkeur met Microsoft’s Azure Data Catalogue omdat deze technologie ook van pas komt bij het ontwikkelen van beleid voor security en automatisering.
Het bewerkingsregister waarin de gevonden databronnen en de verwerkingsactiviteiten worden gecombineerd, kan bijvoorbeeld in Excel of Word worden gemaakt.
Valid heeft de mensen, de kennis, de methode en de ervaring in huis om te helpen snel en duurzaam compliant te worden. In de Vier Stappen Workshop gaan we met mensen aan tafel om de maturity van de organisatie op onderdelen te bepalen. We definiëren gerichte vervolgstappen om doelmatig te werk te gaan. Het resultaat is breder dan duurzame compliance aan de AVG; het raakt andere domeinen van de bedrijfsvoering. De ‘bijvangst’ bestaat uit betere kwaliteit van de bedrijfsprocessen, minder beslag op IT-resources, goede reputatie, minder risico’s, handhaving van de concurrentiepositie.
Ook om die reden is het zaak snel te handelen. Wij zijn er klaar voor! Zullen we mikken op Klaar voor Kerstmis?
- In onze volgende blog behandelen we de tweede fase, die van de Registratie. Je zult zien dat dit een relatief kleine stap is vergeleken met de Inventarisatie. Blijf ons volgen!
![]()
Workshop op maat
Valid heeft een praktische workshop ontwikkeld over ‘AVG-compliance in Vier Stappen’. Op basis van de bedrijfssituatie doen we een eerste inventarisatie en vullen we het stappenplan in met concrete acties en resultaten. Laat een commentaar achter als je belangstelling hebt in de workshop!
AVG Kennissessie
Op 31 oktober organiseert netwerkorganisatie Flevum Executive een event rondom de Algemene Verordening Gegevensbescherming. Collega Martijn neemt tijdens deze bijeenkomst het podium. We hebben een methode ontwikkeld waardoor privacy-gevoelige gegevens - gestructureerd of niet! - te identificeren zijn, welke we toe zullen lichten aan de hand van een praktijkcase. Martijn van Grieken, Senior Data Scientist, zal Valid vertegenwoordigen. Lees hier meer over deze dienstverlening.
Interesse in deze sessie? Bekijk de pagina van Flevum Executive.
![]()
Klik hier voor meer informatie over Valid's AVG dienstverlening.
