Stel dat je navigatiesysteem de verkeersinformatie met een vertraging van 30 minuten zou doorgeven, hoeveel verkeersopstopping kun je dan vermijden?
Of als je navigatiesysteem voortdurend met een paar minuten vertraging die ene afslag door zou geven, hoe lang duurt het bij jou voor je naar een nieuw navigatiesysteem gaat zoeken?
En waarom werkt mijn navigatiesysteem nog niet samen met andere navigatiesystemen en sensoren in onze auto’s om bijvoorbeeld die file voor rechtsaf ver van tevoren te herkennen, zodat ik eerder kan acteren.
Dat zijn in principe dezelfde vragen die wij aan onze Business Intelligence omgeving moeten stellen. Nu is jouw vraag natuurlijk hoe we kunnen veranderen van een BI-oplossing die is gebaseerd op batches van data laden naar een BI-oplossing die real-time data aan kan?
Hoe kunnen we ons datawarehouse moderniseren, zodat alle relevante informatie real-time tot je beschikking is – zodat je er de juiste conclusies uit kunt trekken en daardoor nauwkeuriger én sneller tot een besluit kunt komen?
Het antwoord hierop is de Lambda Architectuur.
“De wat-architectuur…?”, hoor ik je al denken.
![]()
Ontmoet de Lambda Architectuur
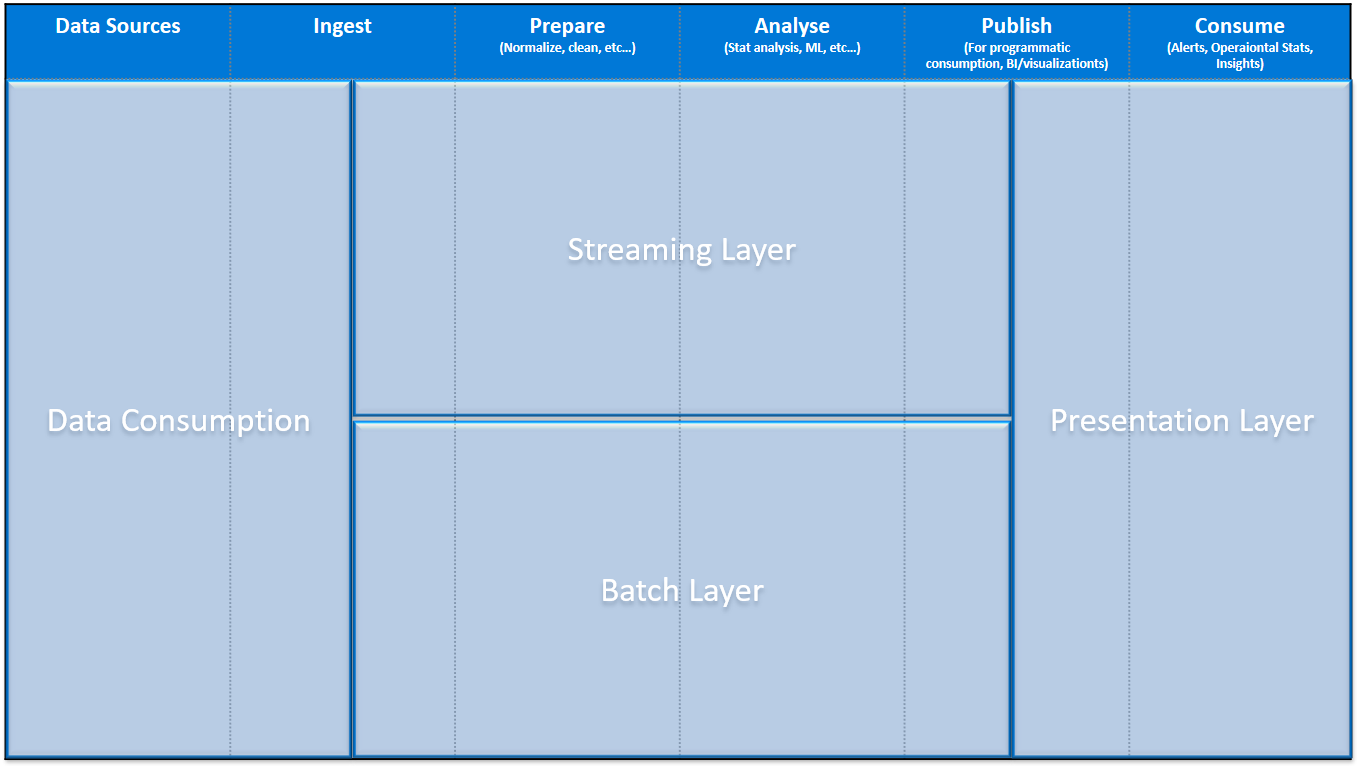
De Lambda Architectuur is een referentie-architectuur voor het combineren van de batch data met de real-time data voor al jouw real-time vragen aan het datawarehouse.
High-level ziet je architectuur er dan als volgt uit:

Data consumption
Onder data consumption verstaan we alle mogelijke databronnen die nodig zijn om aan de informatiebehoefte van een eindgebruiker te voldoen. Dit is zowel interne- als externe data, cloud-born data, (IoT) device data, social data, Google Analytics data etc.
Streaming Layer
De streaming layer wordt gebruikt om real-time data te verwerken, zonder data quality requirements of volledigheid van data. Dit om de data real-time te kunnen analyseren en hierover te kunnen rapporteren, alsmede om de data op te slaan.
Batch Layer
De batch layer bereid alle data één keer per x-tijdseenheid voor en is de “single version of the truth”. Data quality requirements en business rules zijn toegepast en de data staat klaar in bijvoorbeeld een datamart of een kubus.
Presentation Layer
De presentation layer is de laag waar de streaming- en batch data samen komen. Afhankelijk van de informatiebehoefte rapporteer je over de beschikbare data. Bij voorkeur rapporteer je over de batch layer, omdat deze de “trusted” data bevat, echter als je real-time wilt rapporteren gebruik je data van de streaming layer.
Enkele verschillen tussen de streaming- en de batch Layer
|
Streaming |
Batch |
|
Continu data verwerken |
1 x per tijdseenheid data verwerken |
|
Weinig data per flow |
Veel data per flow |
|
Real-time data |
Historische data |
|
Snelheid: “What we want right now” |
Correctheid: “Single version of the truth” |
Het Moderne dataplatform & de Lambda Architectuur
De informatiebehoefte die een eindgebruiker heeft staat centraal, de architectuur heeft als doel deze informatiebehoefte te vervullen. Het moderne dataplatform richt zicht niet alleen op datawarehousing, maar ook op data science, advanced analytics en application development. Het kijken naar de data van gisteren is niet minder belangrijk geworden, maar samen met bijvoorbeeld het real-time analyseren van data en het voorspellen van de toekomst kunnen beslissingen nog beter en sneller genomen worden.
We merken dan ook dat de BI/Big Data/IoT-projecten die we doen niet alleen maar “Business Intelligence & Advanced Analytics” projecten zijn, ook onze eigen Valid Development Factory sluit steeds vaker aan. Bijvoorbeeld om data via een ServiceBus-oplossing aan te bieden aan een Azure Stream Analytics job of om streaming data te verrijken met een Machine Learning output en terug te koppelen aan een website om een “next best action” aan te bieden.
Bij Valid hanteren we het uitgangspunt dat we alle “raw” data opslaan. Onder andere om de data te kunnen verwerken in het batch proces, onze Data Scientists toegang te geven tot de data maar ook omdat men vaak nog niet weet welke waarde men uit de data kan halen. Wat we wel weten: Als we het niet opslaan kunnen we er niets meer mee! Data verwijderen kan altijd nog.
De architectuur maakt het mogelijk om naast de on-premises Microsoft BI data warehousing tooling die we bij Valid gebruiken (SSIS, SSAS, SSRS, APS) ook gebruik te maken van al het mooie dat de Microsoft Cortana Intelligence te bieden heeft. Denk hier bij aan Azure Stream Analytics, Azure Machine Learning, Azure HDInsight, Azure SQL Datawarehouse en Power BI. Het voordeel van de Cortana Intelligence componenten is dat deze schaalbaar zijn, op het moment dat je veel compute power nodig hebt, schaal je deze op, om ze daarna weer terug te schalen.

![]()
De voors en de tegens
Enkele voordelen van de Lambda architectuur zijn:
- Streaming data en batch data kan verwerkt worden;
- On-premises & Cloud software gebruiken;
- Alle data wordt bewaard;
- Analyseren en rapporteren op basis van batch data, streaming data of een combinatie hiervan;
- Realtime analyseren en rapporteren;
- Data scientists kunnen analyses doen op alle (on)gestructureerde (big) data sets.
Een nadeel dat ik wel eens hoor is dat er van veel verschillende software gebruikt gemaakt wordt, maar ook daar hebben we een oplossing voor. We kiezen zo veel mogelijk voor standaard Azure-componenten en indien de techniek het toestaat gebruiken we SQL als query language.
Zelf ervaren hoe een Lambda Architectuur jou in staat stelt om je bedrijf real-time te sturen, schrijf je in voor onze Bring Your Own Architecture workshop!

![]()
