Iedereen denkt dat als je maar genoeg data hebt dat je de toekomst kan voorspellen. En ik ben het daar eigenlijk wel mee eens.
Vroeger gebruikte men een glazen bol om de toekomst te voorspellen. Tegenwoordig hoeft dat niet meer, want er is data! Weg met de glazen bol, je kunt je data beter koken!
In de vorige blog hebben we het gehad over data science en het verhaal achter de data. Laten we nu eens kijken naar de voorkant van de data. Nadat je de data tot je beschikking hebt, wat doe je dan? Wanneer je genoeg data tot je beschikking hebt kun je patronen en trends identificeren, waaruit je conclusies over de toekomst kunt trekken.
Machine Learning
In deze blog wil ik me graag focussen op de pre-analyse van de data en het Machine Learning (ML) onderdeel van data science. Er zijn duizenden artikelen te vinden over Machine Learning, dus ik beperk mezelf hier tot wat basis informatie.
Wat is Machine Learning?
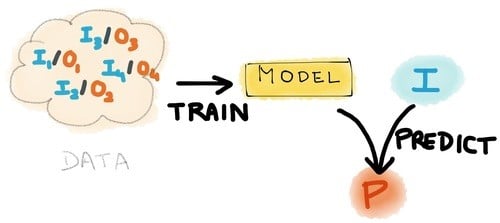
Wat is Machine Learning nou precies? Dat blijkt de hoofdvraag te zijn. Laatst las ik de beste analogie over Machine Learning; Machine Learning is het best te vergelijken met een computer gestuurde etenswaren-machine. Je voedt de machine met ingrediënten (oftewel; data, in dit geval noemen we dat de training set) en na wat algoritmisch zoemen en kraken; Voilà! Eten! Of in het geval van Machine Learning een correlatie of patroon dat het algoritme heeft “geleerd” van de training set.

De machine wordt dan gevoed met een nieuwe dataset en op basis van wat het heeft geleerd worden er meer correlaties, patronen, aanbevelingen of zelfs oordelen geproduceerd. Oordelen zoals; deze persoon heeft z’n adres veranderd, dus heeft een hogere kans om z’n huidige werkgever binnenkort te verlaten (ook wel bekend als HR Analytics). Of, gebaseerd op “deze data” zouden we die persoon veilig een lening kunnen verstrekken. Of zelfs “draaideur X” in “gebouw A” moet nu worden vervangen anders gaat ‘ie over een week kapot.
Je traint een computer op een grote hoeveelheid data, en daardoor leert die computer structuren te herkennen.
Op deze wijze kan de machine voorspellingen aandragen met betrekking tot de data die je de machine gevoerd hebt. Hoe accuraat en betrouwbaar de voorspelling is, hangt sterk samen met de kwaliteit en de beschikbaarheid van de data. Want hoe goed je algoritme ook is; “Garbage in = Garbage out”. Dus je moet scherp zijn op wat je de machine voedt. Hier geldt ook de analogie met de etenswaren-machine: ook al heb je het beste apparaat ter wereld, als de ingrediënten over datum zijn zal die heerlijke taart niet te pruimen zijn. Ook al ziet ‘ie er nog zo goed uit. Je kunt een ML model met 95% accuratesse ontwerpen, maar dat betekent nog niet dat je resultaten betekenisvol zijn. In tegendeel zelfs, het kan er tot leiden dat je de verkeerde beslissingen neemt. Dat is waarom je zeker moet zijn van de kwaliteit van de data, het is de meest belangrijke stap nog voordat je een model gaat creëren.
Data munging
Het prepareren van data (a.k.a. Data Munging) is het meest tijdrovende deel van een data science project. In 99% van de gevallen is data niet “schoon” en dus niet gereed voor analyse. We moeten dus, zoals ik het noem, een pre-data analyse uitvoeren. Prepareer de ingrediënten voordat je ze in de pan doet.

Dus, voordat we starten met het bouwen van een voorspellend model moeten we de data voorbereiden. Net als bij koken; je marineert eerst het vlees, of wast eerst de groente voordat je ze gaat bereiden. Hetzelfde doen we met data, in vier stappen voeren we de “pre-data analyse” uit.
Stap 1: Missing Values
Eerst moeten we op ontdekkingsreis door de data, om missing values te identificeren en te behandelen. Er zijn verschillende manieren waarop je missing values in een dataset kan behandelen, de manier die je kiest is afhankelijk van hetgeen je wilt bereiken. Soms kun je rijen met ontbrekende data gewoon verwijderen, ze vullen met een specifieke waarde (bijvoorbeeld het gemiddelde) of interpoleren (bijvoorbeeld lineair).
Stap 2: Berekenen
Soms is het nodig om een aantal berekeningen te doen om waardes te vinden. Bijvoorbeeld om tot de som van een waarde te komen, de hoogste waarde uit de dataset te vinden of soms zelfs om de waardes te sorteren, gebaseerd op een specifieke maatstaf. Deze, en nog vele andere, mathematische oefeningen zijn erg belangrijk voor de analyse. Het is makkelijker om hoog-over conclusies te trekken als je dataset geaggregeerd is.
Stap 3: Uitschieters
Grote datasets hebben vaak waardes die of foutief zijn, of enorme uitschieters, welke de relaties in het model scheef trekken. Om de uitschieters er uit te pikken is het belangrijk om de data goed te onderzoeken en te visualiseren. Je moet er ook voor oppassen dat de uitschieters die je hebt geïdentificeerd oprecht zijn en behandeld moeten worden, en niet dat het indicatoren zijn die in je model meegenomen moeten worden. Ook voor uitschieters geldt, net als bij missing values, dat er verschillende wijzen zijn om ze te behandelen en dat je, afhankelijk van wat je wilt bereiken, de juiste methode hanteert.
Stap 4: Schaalgrootte
De laatste stap voordat we het model bouwen is om de numerieke variabelen te identificeren en te normaliseren. Oftewel; de waarden moeten dezelfde schaalgrootte kennen. Alleen dan is het mogelijk om een goede vergelijking te maken en “veilige” resultaten te behalen. Deze stap doe je altijd na het behandelen van de uitschieters. Het is ook belangrijk om ervoor te zorgen dat je na het “schalen” de relatieve relaties tussen de numerieke variabelen niet verliest.
Een introductie van Machine Learning

Na het voorbereiden van de dataset, dus na de tijdrovende maar zeer belangrijke stappen, zijn we eindelijk zover om ons voorspellende model te creëren met behulp van Machine Learning. Er zijn verschillende ML algoritmes die je kunt gebruiken voor de voorspellende modellen. Ik beperk mezelf hier tot de twee basis types: Classificatie en Regressie.
Classificatie
We gebruiken classificatie om antwoorden te voorspellen als Yes/No of True/False. Dus een vraag als, om HR Analytics maar weer aan te halen; Verlaat deze medewerker dit bedrijf binnen zes maanden? Of; Zal deze klant reageren op deze promotionele actie? Maar ook op het gebied van bijvoorbeeld fraude detectie, tekst categorisatie en nog veel meer.
Regressie
We gebruiken Regressie om echte waarden te voorspellen. Het wordt met name gebruikt om een schatting te maken van echte waarden gebaseerd op continu variabelen. Een voorbeeld zou kunnen zijn om de verkopen van een afdeling te voorspellen, of (daar is ‘ie weer, HR Analytics) hoe lang een medewerker nog bij dezelfde organisatie werkzaam is.
Tot de volgende blog!
In mijn volgende blog probeer ik de belangrijkste basis-features van dergelijke ML algoritmes er uit te lichten. Tot die tijd; was je ingrediënten goed voordat je gaat koken! Stay Ahead & Stay Tuned voor m’n volgende post.
Deze post maakt onderdeel uit van onze Data Analytics practice.
